What happens if you have a single AWS RDS instance running in production and it's looking like this?

Maybe with a replica that looks like this?
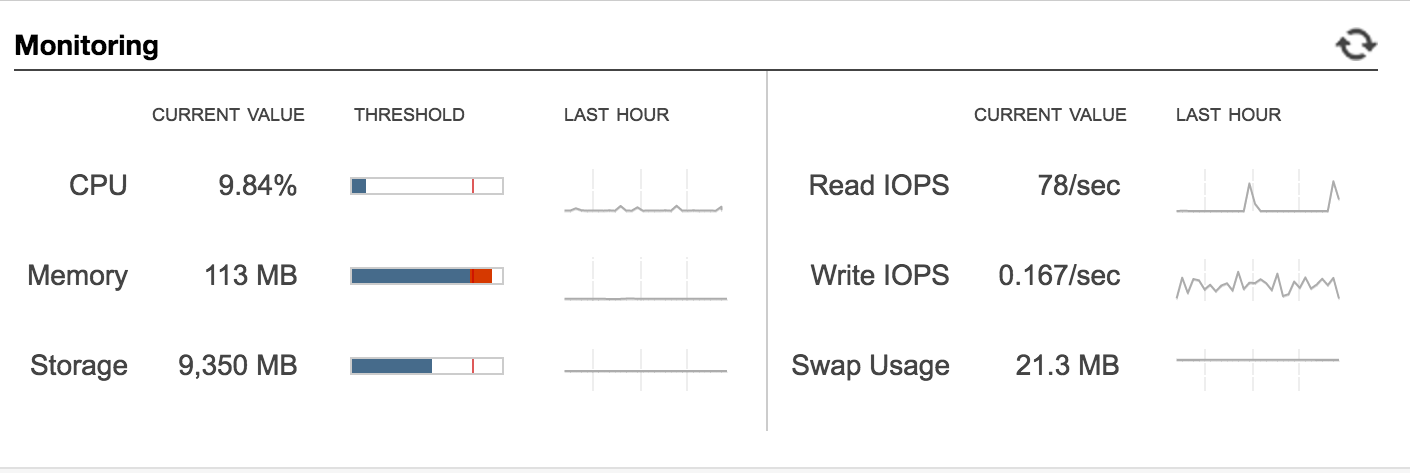
And a dev database that looks like this?
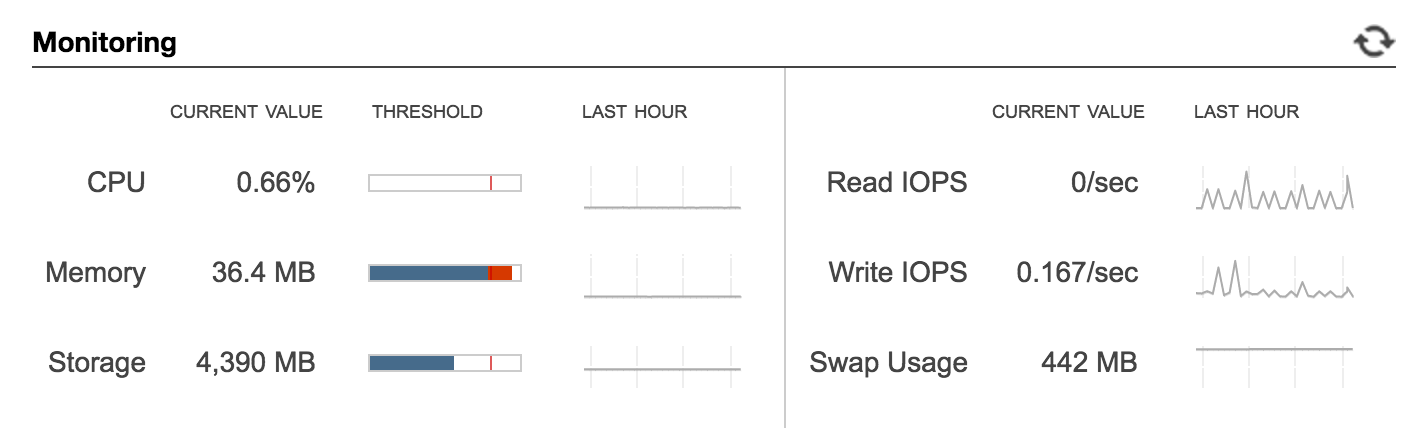
Congratulations! You need to beef up all your databases!
Step 1: Sizing
You only have one instance in each case and you will need to know what an outage, if there is any, will look like for production and have a good guestimate for what the outage will look like. To do that, you primarily need to know if your databases are multi-AZ or not. If they are, then the database will failover as part of the upgrade and this will significantly decrease your downtime. You will also want to know what you want your new instance sizes to be (RDS Sizing FAQ).
For sizing, I made use of our CloudWatch database to account for how quickly the database was growing and trying to figure out what our future growth would look like as best as I could approximate so I didn't find myself doing this again next quarter. Ultimately, I planned to upgrade the mix of db.t2.mediums and db.t2.smalls to all db.r3.larges. What I considered in switching the type (t2 to r3) of database is that we did not need the burst capabilities of the t2 series - in fact, we historically had very, very low CPU usage period. So I opted for an instance type that was memory optimized instead of CPU utilization. To read up on the different DB instance types, please check out the AWS RDS DB Class doc). I also doubled the disk on prod and upped the read-only replica and dev to match.
It's probably worth mentioning that when you create a read only replica of your production database with AWS it is not lock-step with prod in terms of instance type / size. You can have a read only replica that is larger or smaller than your production database, as your usage requires.
Step 2: Demoing the outage
After figuring out what sizes I wanted to use, I needed to do a test upgrade in dev to see how long it took to upgrade and see how long the outage lasted so I could plan accordingly for production. The production database is multi-AZ, but the dev database was not. I changed dev to a multi-AZ database for the purpose of the upgrade and it thankfully it took under 15 minutes. So, good to know.
Now it's time for the development upgrade itself - make sure that you're only upgrading your development database at this point.
Development.
No one likes an accidental, surprise, production outage if it can be helped.
Go into the AWS console, choose your development database and Modify. Up the instance type to the appropriate size and your disk if needed. If you would like to apply the changes immediately (I did), then click "Apply Immediately" at the bottom. Otherwise, the changes will apply during whatever maintenance window you have already chosen for your instance. Click "Continue" and, after reviewing the changes, click "Modify DB Instance".
And we're off to the races!

Ok, so it isn't the fastest race.
In order to determine the length of the outage I ran a curl statement against our app API. Even though the total upgrade time was roughly one hour, it took 15 minutes to start the failover and it was only one minute to complete the failover. Based on the curl, the only downtime when during the minute of failover. Feeling confident, looking good. Production upgrade window will be an hour with an expected outage of only about a minute.
Step 3: The actual upgrade
Depending on your needs, you may be able to upgrade production now or you'll need to schedule an outage. Make sure you include the time to make your production database multi-AZ if it is not already. (It should be.)
Once you have that figured out, make the same changes to your production database as you did to your development database. Once the production upgrade has completed, upgrade the read only replica if you have one. In our case the downtime was one minute for production and another minute for the replica, and the total upgrade time for each was the same as dev: one hour (so a two hour window with a few minutes of downtime).
Step 4: Profit
By now your instances should be SUPERBEEFED. They may look a bit like these:
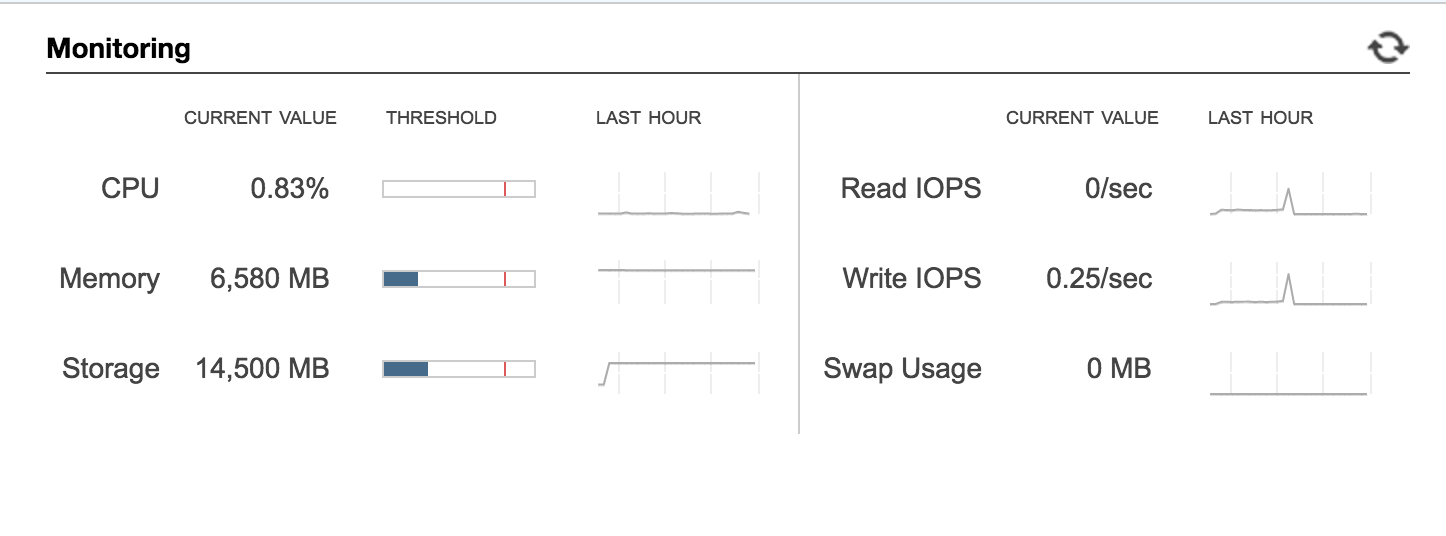
Development
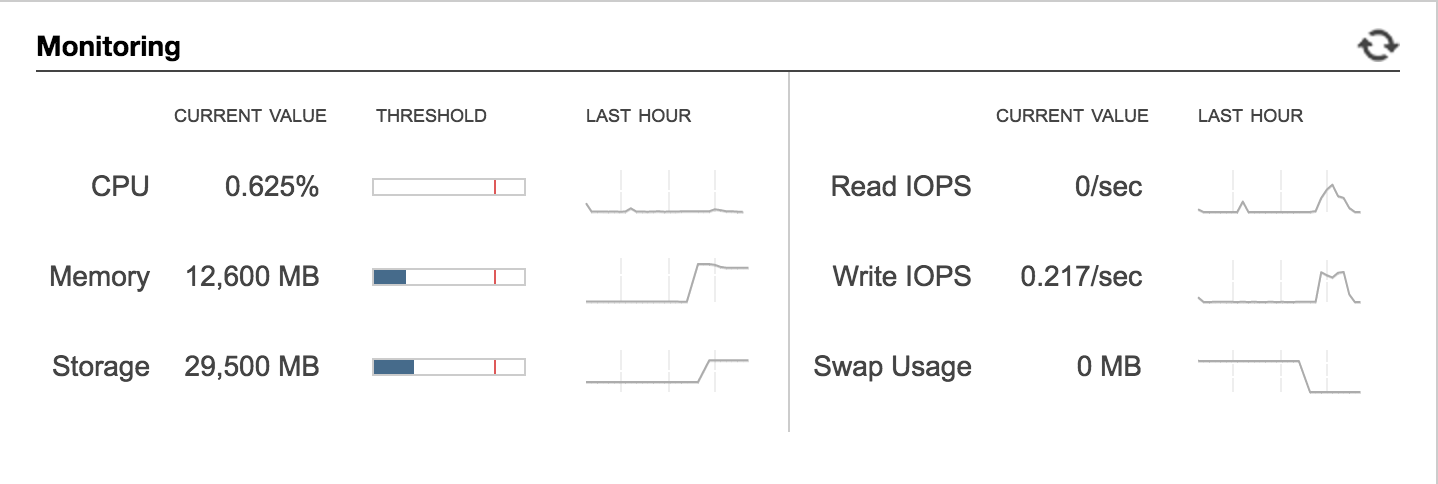
Replica
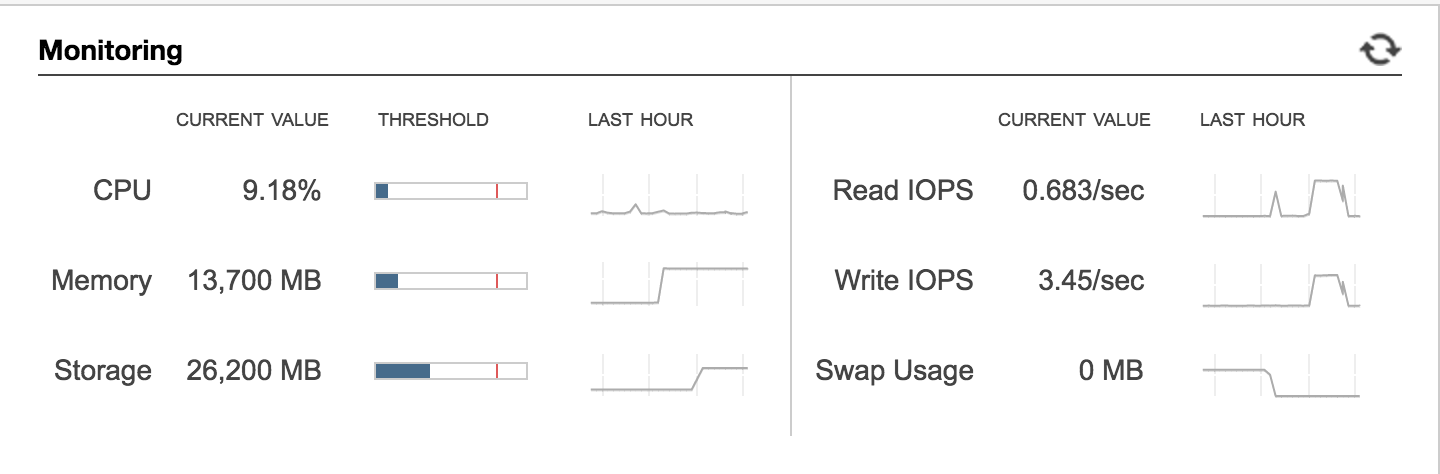
Production
Tons o' free space, free memory, and no more swap usage. Hooray!

Documented on my frequently used assets page.