So I like yellow as a general rule. Apparently, Amazon is also a fan:

Might be a bit yellowish orange.
Unfortunately, I have to say I don't like it so much in this context:
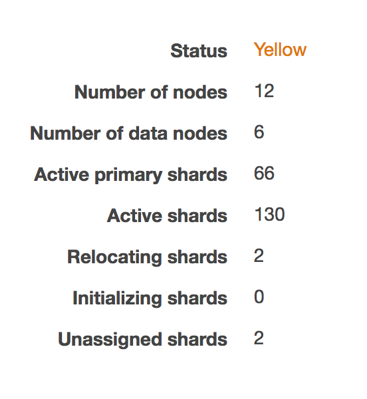
Is it just me or is that the exact same shade of "yellow" as in the logo?
According to the AWS documentation, the yellow status means just what I'm seeing here: unassigned / unallocated shards. The summary shows that the AWS ES cluster is already trying to recover from the problem by relocating the shards. To get a little more context, I hopped into the AWS ES CloudWatch Monitoring view:
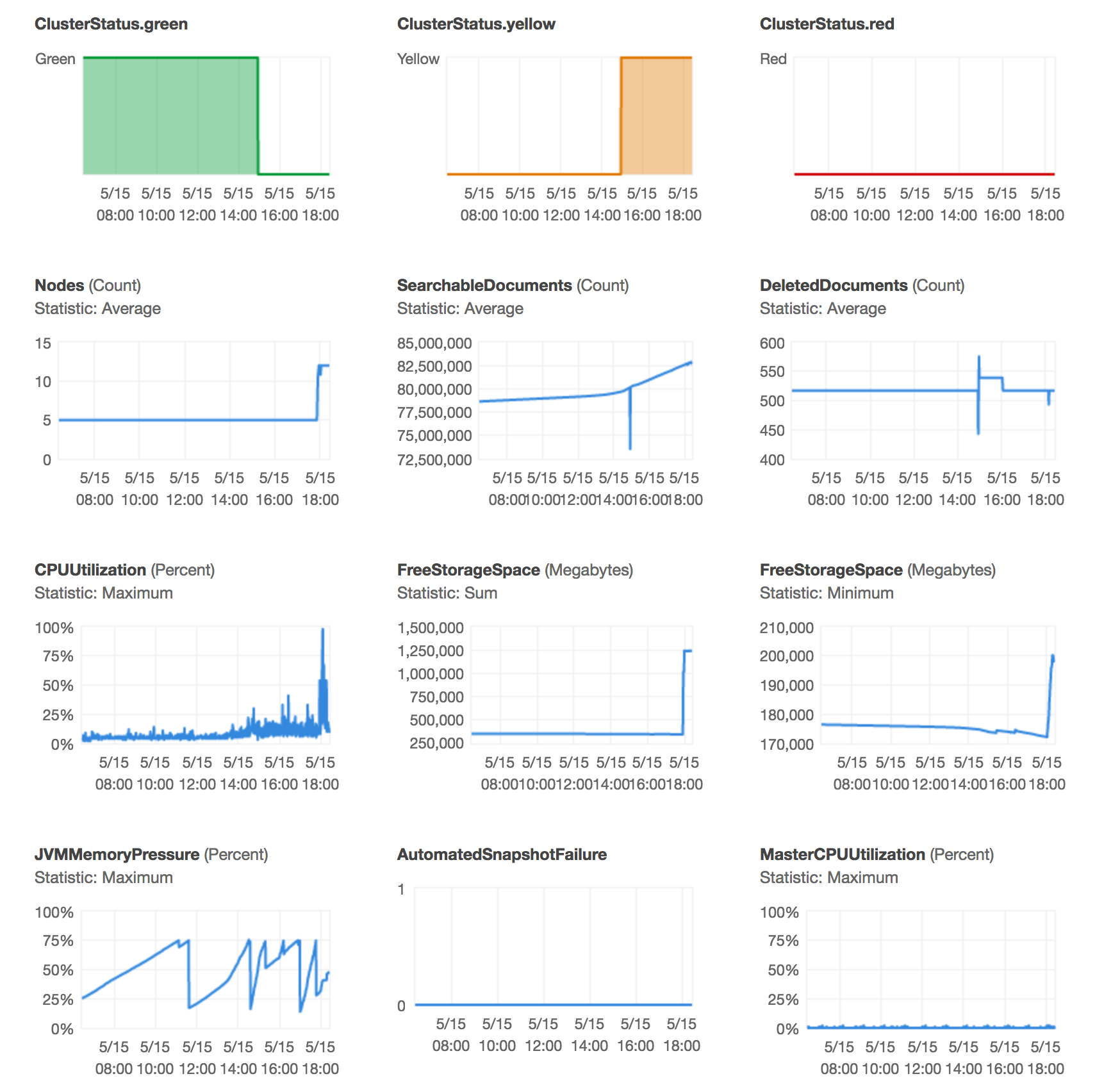
That looks like a ton of information, but right now the main concern is the node count and the minimum free space. AWS ES "automagically" tried to heal by upping the instance count and this drastically increased the minimum free storage space. The reason this is relevant is that Elasticsearch will not write to a data node that is using more than 85% of its free disk space. In this cluster, the original configuration was three master nodes and two, zone aware, data nodes. Each node has 256 GB of space, so when AWS ES reports that the minimum free space is about 170 GB, that just means that the smallest amount of free space available on any node in the cluster is 170 GB. Since the nodes are 256 GB that means that only 66% is in use, well under the 85% threshold. That said, the first thing I did to rectify the situation was add two more data nodes:
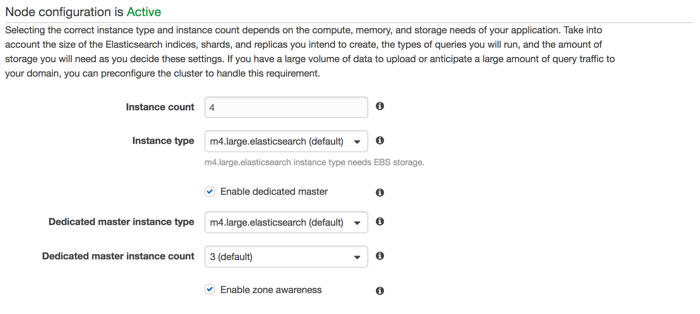
Unfortunately, 24 hours later, no dice. I have more storage space now but the cluster is still yellow. Which makes me blue.
Going back to the earlier AWS ES doc page, they direct you to read up how to change index settings without any additional context or information. Helpful? Ish?

So I needed to know which shards were failing to allocate:
$ curl -s -XGET 'my-cluster.es.amazonaws.com/_cat/shards?h=index,shard,prirep,state,unassigned.reason' | grep -i unassigned
logstash-2017.05.15 1 r UNASSIGNED ALLOCATION_FAILED
logstash-2017.05.15 3 r UNASSIGNED ALLOCATION_FAILED
Then I reduced the index replicas for these shards down to 0 and then increased them back up to 1:
curl -s -XPUT 'my-cluster.es.amazonaws.com/logstash-2017.05.15/_settings' -d '{"number_of_replicas": 0}'
curl -s -XPUT 'my-cluster.es.amazonaws.com/logstash-2017.05.15/_settings' -d '{"number_of_replicas": 1}'
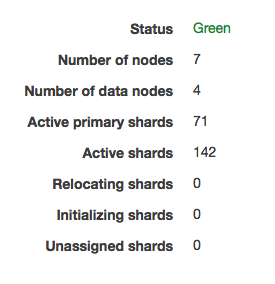
The status of the AWS ES cluster was immediately returned to green, just the way I like it:
Quick Note on Failing AWS Elasticsearch Endpoints
While I was researching this issue, I did come across several Elasticsearch endpoints that AWS ES does not support. Although potentially, but not necessarily, useful in this case I still wanted to point out that it looks like AWS ES does not support the _cluster/settings, _cluster/reroute, /_open, or /_close endpoints. One example post is on the AWS Developer forums here. (Fair warning, you'll need to be logged into AWS to see the post.)
Just a heads up in case you find yourself needing these at any point.
Also feel free to read that header in Trump voice for added humor. You know you want to.
Quick Auth Protip
You may have noticed that there aren't any auth headers in those curl statements. The reason isn't because I left them out for security, it's because of the way that I wrote my Access Policy. Specifically, the instance that I was working from was an admin host that I set up for this purpose, so I added that instance's public IP to the policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:{{REGION}}:{{ACCT NUMBER}}:domain/{{NAME}}/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"a.b.c.d"
]
}
}
}
]
}
This is a very open policy that allows me to do anything I'd like to my ES domain from the instance with public IP a.b.c.d. So if you do use this policy, USE WITH CARE. Depending on your separate needs it might be more prudent to setup different access policies for different IPs.

Documented on my frequently used assets page.